
RapidFire AI is a company that accelerates AI application development by enabling data scientists and ML engineers to run many models and hyper-parameter experiments in parallel, monitor them in real time, and dynamically prune or clone promising runs, all while abstracting away the cluster-infrastructure complexity. Pulse 2.0 interviewed RapidFire AI co-founder and CTO Arun Kumar to gain a deeper understanding of the company.
Arun Kumar’s Background

Could you tell me more about your background? Kumar said:
“I am a co-founder and CTO of RapidFire AI. We are building an open-source AI experimentation engine that makes it dramatically easier to customize large language models (LLMs) and deep learning (DL) models for one’s AI use cases. Our system helps AI practitioners compare numerous configurations in parallel no matter how many GPUs they have and handles large models and datasets across GPUs automatically and efficiently. This cuts down the time to get much better eval metrics for AI use cases.”
“I am also an Associate Professor in Computer Science and Engineering and the Halıcıoğlu Data Science Institute at UC San Diego. My research focuses on data management and systems for ML/AI-based analytics. My work has been adopted by companies such as Google, Meta, Oracle, and VMware.”
“I am passionate about bridging the gap between research and practical AI applications across all sorts of domains: sciences, humanities, healthcare, enterprises, tech companies, and nonprofits. I enjoy creating software that helps more domains adopt cutting edge AI.”
Formation Of The Company
How did the idea for the company come together? Kumar shared:
“The idea for RapidFire AI came from our own experiences with AI applications in both domain sciences and industry. My co-founder, Pradyumna Sridhara, and I saw how time-consuming and complex it was to experiment with DL models for public health use cases at UC San Diego with TB-scale labeled datasets. Even small tweaks in the label semantics or model architectures would take weeks to test, slowing down innovation. Our collaborators at companies such as VMware, Meta, Netflix, etc. also reported similar issues causing resource wastage.”
“We set out to create a system that makes AI experimentation much faster, more flexible, and scalable so that AI teams can iterate quickly, be incentivized to experiment more, and get better results without being bottlenecked by infrastructure. RapidFire AI was born out of that vision: empower AI researchers and practitioners with tools that bridge the gap between the promise of modern AI models and actual impact on use cases.”
Core Products
What are the company’s core products and features? Kumar explained:
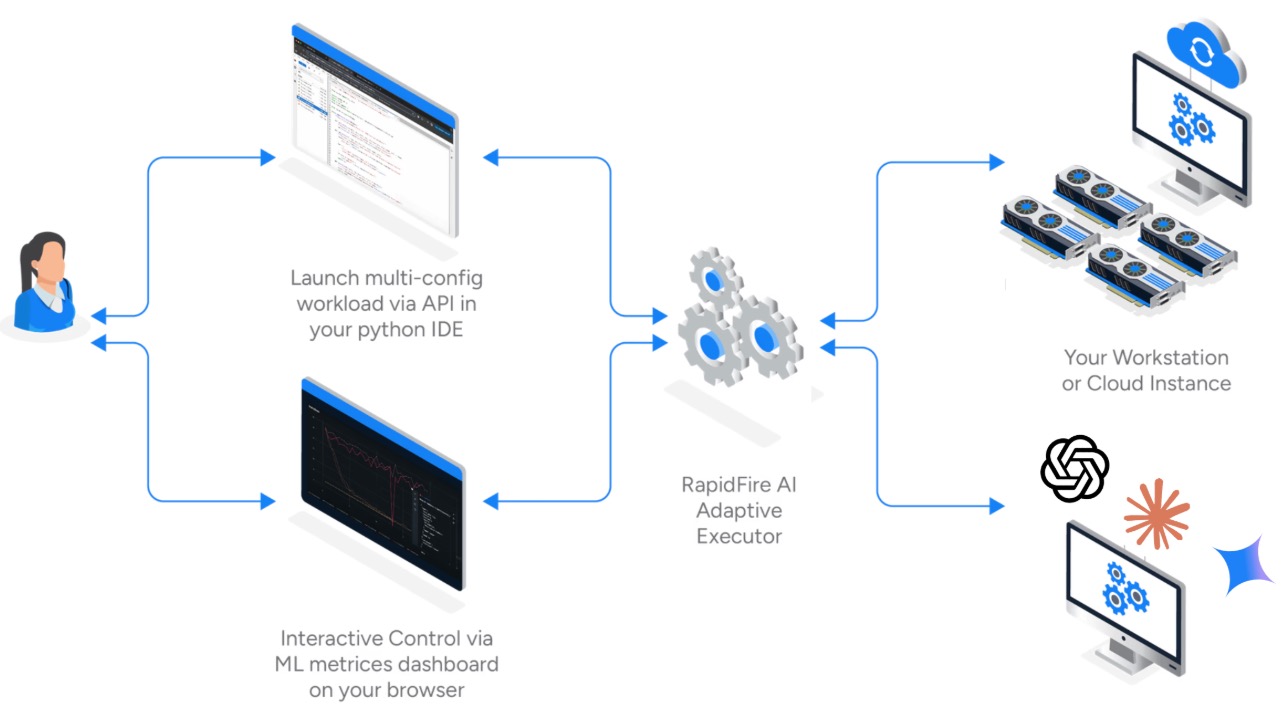
“At its core, RapidFire AI is an open-source experimentation engine that makes it faster and more systematic to customize LLMs/DL models. Instead of running one configuration at a time and waiting days for results, the user can compare dozens of combinations of knobs related to the data/prompt preprocessing, model/adapter specifics, or trainer hyperparameters in parallel, even with only a few GPUs, and see what works in real time. We call this “hyperparallel” exploration.”
“They can stop weak runs early, clone promising ones in flight, and warm-start new combinations without restarting from scratch and without needing to juggle separate processes or clusters. RapidFire AI wraps around familiar PyTorch and Hugging Face APIs, with native support for TRL workflows such as SFT, DPO, and GRPO for fine-tuning and post-training.”
“We recently extended our system to Retrieval Augmented Generation (RAG) and context engineering workflows as well so that AI teams can use LLMs grounded on their in-house data. It is the same principle–hyperparallel experimentation and dynamic control over runs in flight–but now applied to RAG knobs that affect eval metrics: prompt schemes, data chunking, embedding, retrieval, reranking, etc. It also works for closed model APIs such as OpenAI instead of self-hosted models on GPUs. In short, RapidFire AI transforms AI customization from a mystical guessing game into a methodical engineering process.”
Challenges Faced
Have you faced any challenges in your sector of work recently? Kumar acknowledged:
“One of the biggest challenges in the AI sector is the mindboggling pace of change–new models, post-training methods, and infrastructure frameworks appear almost weekly. For a company building AI experimentation tools, that means constantly adapting and evolving to stay relevant at the cutting edge.”
“We have addressed this by keeping RapidFire AI modular and open-source, built directly on top of industry standard tools: PyTorch, Hugging Face, MLflow, LangChain, Ray, etc. This ensures that customers can continue to take advantage of new developments and updates by the wider community without rewriting core logic.”
“Another challenge has been educating AI users about the importance of systematic experimentation, almost as important as model choice itself. We have overcome that by releasing strong documentation, open tutorials, and collaborations with early users who help demonstrate the value in real-world terms–faster cycles, lower compute costs, and better AI application outcomes.”
Customer Success Stories
When asking Kumar about customer success stories, he highlighted:
“As one public example, the Data Science Alliance is a nonprofit focused on community and social-impact projects. Their team works with customers on a range of AI projects. Using RapidFire AI, they have cut their development cycle times by 3x. What used to take a week now takes about 2 days. They can run multiple configurations side-by-side to see what performs best. Ryan Lopez, Director of Operations, credits their ability to iterate at hyper speed to RapidFire AI. ‘It gives us a really structured, evidence-driven way to do exploratory modeling work.’”
“We have also published benchmark results on fine-tuning for a customer support Q&A chatbot where RapidFire AI offers about 20x gain in experimentation throughput, allowing better eval metrics to be reached in less time. We will be releasing more public case studies of RapidFire AI’s benefits from our ongoing design partnerships soon.”
Funding
When asking Kumar about the company’s funding details, he revealed:
“We raised $4 million in pre-seed funding from a syndicate with .406 Ventures, AI Fund, Osage University Partners, and WillowTree Ventures. This allowed us to accelerate development of our open-source experimentation engine and expand our team to support more users across enterprises, startups, and research labs. Our focus has been on building a strong foundation, delivering real value to users, demonstrating clear application gains, and expanding adoption across industries. The traction we have been seeing gives us confidence in the long-term business opportunity here as we continue scaling both our technology and customer base.”
Total Addressable Market
What total addressable market (TAM) size is the company pursuing? Kumar assessed:
“RapidFire AI addresses a fast-growing, massive market for AI customization. Gartner estimates that the spending on Generative AI models in 2025 to be $14 billion, with $1.4 billion being spent on specialized models including domain-specific customizations. As enterprises move from using generic foundation model APIs or pretrained open models to building domain-specific models and/or RAG pipelines, they need better ways to fine-tune, evaluate, and ground those in their own bespoke data for their own bespoke eval metrics. RapidFire AI sits right at the heart of that process–helping AI teams experiment faster, control costs, and bring trustworthy AI into production.”
Differentiation From The Competition
What differentiates the company from its competition? Kumar affirmed:
“Popular tools such as MLflow and Weights & Biases help you track or monitor experiments. Some allow you to launch configurations in a task-parallel manner, but bound by the number of GPUs you have, and stop some runs early. But RapidFire AI is the first to enable you to launch as many configurations you want in one go even on a single GPU and control them all in flight in real time. Our engine makes it seamless, maybe even enjoyable, to experiment more with configurations, instead of treating it as a chore or afterthought. Not only can you stop weak runs early, you can revisit them later, and clone and modify promising runs in flight to warm start new variants–all without extra GPUs or DevOps overhead. Such control operations can be performed interactively from the notebook or the dashboard, partially automated with bespoke scripts, or fully automated with AutoML procedures.”
“It is not just a faster engine–it is a qualitative leap to a different mindset of AI customization that makes it a more systematic, adaptive, and evidence-driven process rather than ad hoc trial-and-error. That is what makes RapidFire AI unique: it lets AI teams boost their impact on their application, not just run one model faster or passively log what they have run.”
Future Company Goals
What are some of the company’s future goals? Kumar concluded:
“Our focus is on deepening RapidFire AI’s integration with the ecosystem of tools that AI developers already love–Hugging Face, Ray, and LangChain in particular. Our open-source engine wraps around the Hugging Face TRL and PEFT APIs for multi-config comparisons in fine-tuning and post-training workflows. Likewise, it wraps around the popular LangChain and OpenAI APIs for multi-config comparisons of agentic RAG and context engineering workflows.”
“We are also extending the backend to integrate more deeply with Ray so that teams can scale their workflows, leverage Ray Data for complex preprocessing, and serve their customized LLMs with Ray Serve all in one place. We will keep expanding support for more AI customization workflows, dashboards, and backends based on community and customer feedback. Our goal is to make RapidFire AI the system of choice for impactful AI customization via rapid experimentation, from single-machine research to production deployments at scale, from RAG inference to fine-tuning to full training.”